Prešovský samosprávny kraj (PSK) zriadil v roku 2019 analyticko-strategické oddelenie „Inštitút rozvoja,, pričom medzi hlavné úlohy oddelenia patrí vytváranie analýz pre verejné politiky PSK, poskytovanie otvorených údajov občanom či tvorba rôznych dátových a mapových aplikácií pre občanov alebo pre interné potreby PSK. Aby mohlo oddelenie plniť svoje úlohy, potrebuje pracovať s množstvom interných údajov. Avšak výlučne interné údaje PSK nepostačujú na vytváranie analýz či aplikácií. Na to je potrebné ešte aj ďalšie množstvo údajov od tretích strán (napr. od Štatistického úradu či ÚPSVaR), keďže mnohé údaje dávajú zmysel až v širšom kontexte (porovnané či prepočítané na počet obyvateľov alebo km2). Nuž a aby údaje od týchto tretích strán boli vždy k dispozícii a aktuálne a zároveň aby mali analytici oddelenia k dispozícii vždy čo najširšie možnosti práce s nimi, údaje sa automatizovane replikujú v interných systémoch PSK. A na to slúži automatizovaný import údajov pomocou tzv. harvesterov – automatizovaných „zberačov“ údajov.
Prečo automatizovane
Nasadenie automatizovaného importu predstavuje v podstate malú, ale nie nezanedbateľnú investíciu do IT a tiež záväzok do budúcna, keďže harvester je počítačový program, ktorý treba vytvoriť a udržiavať v prevádzke. Údržba je navyše do určitej miery „riziková“, keďže na ňu vplýva aj to, ako realizujú údržbu svojich systémov spomínané tretie strany (t.j. poskytovatelia údajov). Táto prvotná investícia je zvyčajne vyššia oproti manuálnemu riešeniu, pri ktorom si údaje iba nejako stiahneme a použijeme pre vyriešenie aktuálneho zadania.
Oddelenie však mnohé údaje potrebuje sťahovať opakovane (typicky už spomenuté údaje ÚPSVaR raz mesačne a údaje z ŠÚ raz ročne), keďže „data-driven“ rozhodnutia PSK majú vychádzať z aktuálnej situácie a teda aktuálnych údajov. Robiť toto manuálne by bolo:
- zdĺhavé: druhé, tretie, atď. stiahnutie a uloženie údajov trvá manuálne takmer toľko isto, ako prvé, t.j. už po niekoľkých opakovaniach náklady prekročia výšku investície do harvestera, keďže naopak každé ďalšie automatizované sťahovanie stojí veľmi málo
- náchylné na chyby: stačí napr. po mesiaci či roku pozabudnúť na usporiadanie či drobné prečistenie a mnohé už hotové analýzy či aplikácie nebudú fungovať s novými údajmi
Ak teda analytici na Inštitúte rozvoja dlhodobo pracujú s údajmi, ktoré sú pravidelne aktualizované a ktoré sa využívajú často a na rôzne účely, je vhodné investovať do implementácie harvestera, lebo ušetrí čas a náklady pri aktualizáciách údajov.
Naopak, implementácia harvestera nemá zmysel, ak sa s údajmi neplánuje pracovať dlhodobo, alebo ak poskytovateľ údajov nevie garantovať jednotnú štruktúru a dostupnosť poskytovaných údajov počas dlhšieho obdobia.
Úvodné argumenty za, či proti použitiu harvesterov nateraz uzavrieme, hlbšie zdôvodnenie či ďalšie argumenty vyplynú z podrobnejšieho vysvetlenia fungovania harvesterov v nasledujúcej sekcii.
Ako funguje harvester, všeobecne
Harvester musí splniť tieto hlavné požiadavky:
- pri prvom spustení musí čo najefektívnejšie stiahnuť všetky poskytované údaje o ktoré má používateľ záujem,
- pri druhom a ďalšom spustení musí čo najefektívnejšie stiahnuť už len nové či pozmenené údaje tak, aby kópia u používateľa bola rovnaká ako pôvodné údaje u poskytovateľa,
- harvester musí byť čo najjednoduchší na vytvorenie,
- prevádzka harvestera musí byť odolná voči chybám a výpadkom, t.j. ak nastali nejaké chyby alebo výpadky či už u poskytovateľa alebo používateľa údajov, ideálne má na nápravu postačiť len opakované spustenie harvestera,
- prevádzka harvestera musí byť lacná a efektívna,
- harvester musí byť „ohľaduplný“ aj voči poskytovateľovi, t.j. nesmie zbytočne preťažovať systémy poskytovateľa.
Aby bolo možné tieto požiadavky splniť, tak aplikujeme tzv. „UNIX filozofiu“ a smerujeme k tomu, aby harvester robil ideálne iba jednu vec: udržiaval aktuálnu kópiu údajov „jedna k jednej“ (t.j. v štruktúre a kvalite ako na zdroji, len s minimálnymi zmenami) = „harvestovanie“.
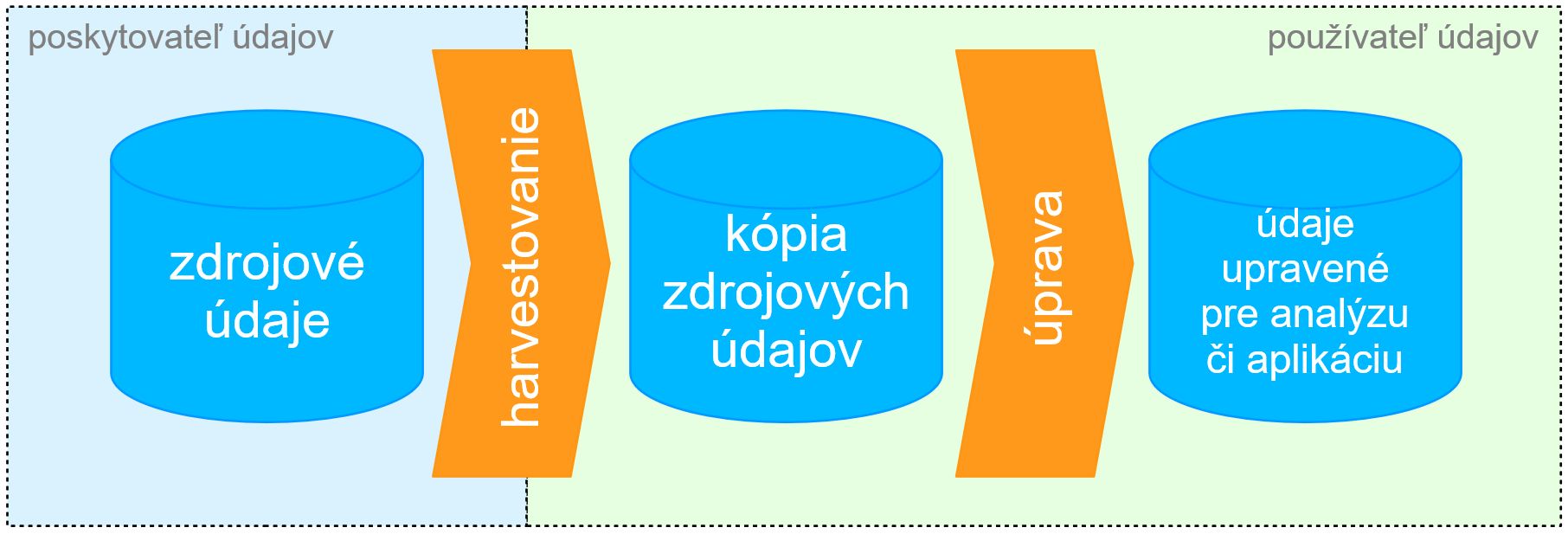
Hotový harvester nasadený na server funguje nasledovne:
- server automaticky spúšťa harvester pravidelne, napr. raz denne (napr. pomocou tzv. `cron`),
- harvester skontroluje dostupnosť nových údajov, ak žiadne nie sú, tak skončí,
- efektívnosť tohto kroku závisí od toho, nakoľko sa dá jednoduchým dopytom na zdroj údajov zistiť, či a čo sa zmenilo. Ak sú zdrojom súbory, tak vie túto úlohu splniť samotný webserver, ktorého sa môžno „opýtať“ napr. pomocou tzv. HEAD požiadavky a zmenu zistiť z ETag hlavičky v odpovedi (oboje súčasť HTTP protokolu). Ak je zdrojom API, malo by API poskytovať volanie typu „je niečo nové od 1.1.2020?“ (kde „1.1.2020“ je dátum, kedy používateľ údaje sťahoval naposledy) alebo „kedy bol zdroj naposledy zmenený?“
- ak nové údaje k dispozícii sú, tak ich stiahne a uloží do internej databázy PSK.
Čistenie, zmenu štruktúry, kombinovanie s inými údajmi a pod. je možné považovať ako niečo, čo do harvestera už zvyčajne nepatrí. Prečo? Vyššie ukázaná schéma predstavuje len zjednodušenú teóriu, kedy jedna analýza či aplikácia používa údaje iba z jedného zdroja. To sa v praxi takmer nikdy nevyskytuje, keďže ako vidno napríklad na príklade mapových aplikácií PSK, údaje PSK, ŠÚ či ÚPSVaR získajú pre občana či úradníkov výrazne väčšiu hodnotu, ak sa zobrazia na mape a prepočítajú na počet obyvateľov daného územia. To už ale vyžaduje kombinovať údaje z viacerých zdrojov a situácia vyzerá skôr takto (pre jednu aplikáciu či jednu analýzu):
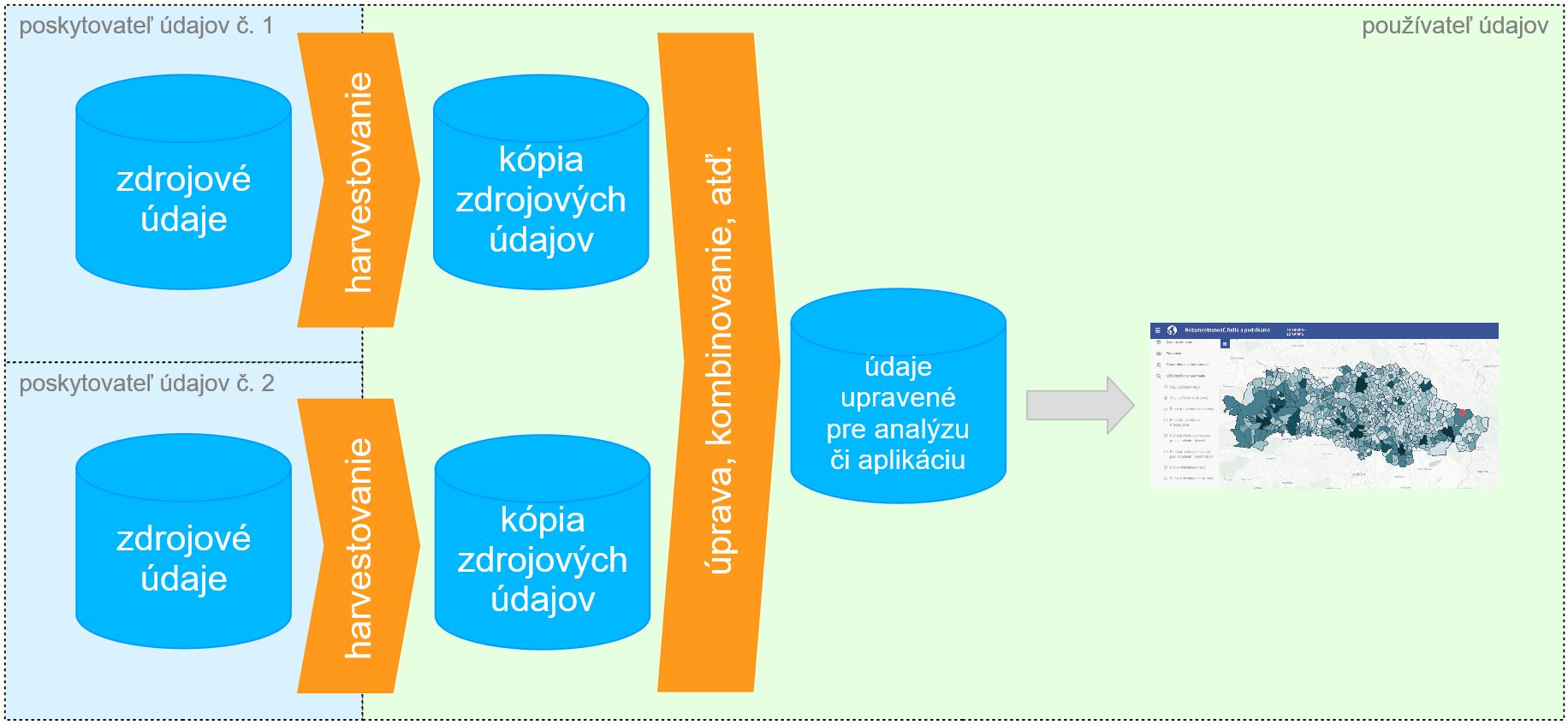
Z uvedeného vyplýva, že sa s harvestermi pracuje lepšie, ak je prevádzkovaný pre každý jeden zdroj údajov práve jeden harvester, keďže napr. pri zmene formátu či API na jednom zdroji stačí meniť jeden malý a jednoduchý harvester bez dopadu na tie ostatné.
Ak si potom predstavíme schému zobrazujúcu aktuálny stav, t.j. že PSK pracuje s desiatkami zdrojov údajov a produkuje stovky analýz a aplikácií (túto schému už naschvál nekreslíme, keďže by to bola len hustá spleť valčekov a šípok), tak pochopíme aj dôvod, prečo čistenie, zmenu štruktúry, či kombinovanie s inými údajmi už realizujeme zvyčajne mimo harvester, v ďalších ETL fázach1Ďalšie ETL fázy môžu využívať rovnaké princípy a spôsoby ako harvestery, dokonca aj rovnakým spôsobom, t.j. napr. jednoduchý Python kód. Alebo aj nie a teda pripadajú do úvahy aj iné postupy či nástroje: SQL view kombinujúci viaceré zdroje a tabuľky, ETL nástroje typu Talend, a pod. Ale o tom niekedy nabudúce.: takéto ďalšie úpravy údajov už závisia najmä od cieľového využitia a rôzne analýzy či rôzne aplikácie vyžadujú iné úpravy tých istých zdrojových údajov a má zmysel ich neviazať na zdroje údajov.
Späť k „prečo automatizovane“
A tu sa môžeme od „ako“ vrátiť späť k „prečo“:
Ak napr. máme Y analýz a aplikácií postavených nad X zdrojmi údajov, tak manuálna alternatíva zvyčajne znamená sťahovať údaje vždy konkrétne na jeden účel (analýza, aplikácia; a to či už vo fáze tvorby alebo neskoršej aktualizácie), čo je na začiatku rýchle a lacné, ale neskôr „vybuchne“: analytici jeden cez druhého opakovanie sťahujú tie isté zdroje a robia s nimi síce podobné, ale predsa len rôzne operácie. Je teda ťažké a drahé udržať manuálne v dobrom stave viac ako „pár“ analýz a aplikácií. Naopak, pri automatizovanom sťahovaní nám stačí udržať v prevádzke len X harvesterov a ušetrený čas venovať tvorbe nových analýz či aplikácií resp. vylepšovaniu tých existujúcich.
Kópia údajov vo vlastných systémoch zároveň rozširuje možnosti práce s nimi: Keďže API použité na zverejňovanie údajov sú primárne realizované pre efektívne šírenie informácií, tak nezvyknú poskytovať funkcie potrebné pre tzv. „analytiku“. Alebo ak by aj takéto funkcie poskytnuté boli, nemusí to byť forma, s ktorou vedia efektívne pracovať napr. analytici PSK. Ak si teda analytici PSK vytvoria kópie vo vlastných systémoch, vedia na analýzy a ďalšie výstupy používať funkcie, na ktoré sú vo svojich systémoch zvyknutí.
Ďalej, ak napr. niektorý z dátových zdrojov vypadne alebo dokonca prestane existovať, tak vlastná kópia údajov pomôže plynulo preklenúť výpadok alebo poskytnúť organizácii čas navyše na hľadanie nových riešení. Analýzy a aplikácie PSK budú fungovať aj prípade, ak by servery ŠÚ či ÚPSVaR nefungovali.
Alebo v prípade, keď prevádzkujeme veľa aplikácií pre mnohých používateľov, tak ich implementácia nad vlastnou kópiou údajov je zároveň ohľaduplná voči poskytovateľom údajov: PSK sťahuje údaje do kópie z ŠÚ či ÚPSVaR iba raz. Ak by naopak údaje analytici či aplikácie PSK sťahovali z primárnych zdrojov opakovane (z pohľadu poskytovateľov zbytočne), tak by vlastne svoje náklady prenášali na poskytovateľov údajov (ŠÚ, ÚPSVaR, a pod.), čo by následne mohlo spôsobiť, že by tie tretie strany prestali poskytovať údaje z dôvodu neúmerne vysokých nákladov. Použitie automatizovaných harvesterov je teda v záujme ako používateľov, tak aj poskytovateľov. Aj preto sme sa v PSK v prípade otvorených údajov rozhodli harvestery implementovať ako Open Source, realizovali ich v spolupráci s poskytovateľmi údajov a sme otvorení spolupracovať na ich ďalšom vývoji a údržbe aj s ďalšími organizáciami.
Aké konkrétne harvestery PSK prevádzkuje
Štatistický úrad
Mnohé údaje Štatistického úradu (ŠÚ) sú dostupné v podobe „kociek“ (cubes) na adrese http://datacube.statistics.sk/#!/lang/sk . Tento spôsob zverejnenia je vhodný najmä na manuálne sťahovanie údajov.
Pre potreby zverejňovania otvorených údajov publikuje ŠÚ aj exporty z kociek vo formáte CSV, ktorých zoznam možno nájsť na https://data.gov.sk/organization/f4787c6f-9fa3-406c-b8d5-d374f1e1f2d3 . Táto forma je vhodná najmä pre údaje, ktoré platia k určitému termínu a neskôr sa už nemenia (typicky výsledky konkrétnych volieb).
Treťou formou zverejňovania údajov ŠÚ je REST API na adrese https://data.statistics.sk/ , ktoré je vhodné najmä pre veľké a priebežne aktualizované údajové kocky (informácie o obyvateľoch a firmách a pod.), keďže poskytuje informácie o dátume poslednej aktualizácie kociek a umožňuje tiež stiahnuť len časť údajov, čo je pri veľkých kockách veľmi užitočná funkcionalita.
Harvester so-harvester využíva práve API data.statistics.sk aby vedel efektívne stiahnuť ako celé kocky na prvé spustenie tak aj už iba nové údaje pri nasledovných spusteniach. Kľúčové pre efektívne fungovanie je, že:
- API ŠÚ poskytuje informáciu o stave aktualizácie kociek, viď napr. https://data.statistics.sk/Cubes/cr3002rr/info/update :
- [{„cube“:“cr3002rr“,“sk“:“v_cr3002rr_00_00_00_sk“,“en“:“v_cr3002rr_00_00_00_en“,„lastupdate“:“21.02.2020″}]
- harvester si v lokálnej kópii pamätá, z akého dátumu má najčerstvejšie údaje (viď so_harvester.py#L59)
- API ŠÚ umožňuje stiahnuť len časť celej kocky, viď napr. https://data.statistics.sk/Cubes/cr3002rr/data/SK041/2019/NOC_TURIS_V_ZAR (údaje iba za celý Prešovský kraj, rok 2019, jeden ukazovateľ):
- {„cube:cr3002rr“:{„Region:SK041“:{„0″:“Pre\u0161ovsk\u00fd kraj“,“1″:“Region of Pre\u0161ov“,“Ukaz:NOC_TURIS_V_ZAR“:{„0″:“Po\u010det prenocovan\u00ed n\u00e1v\u0161tevn\u00edkov v ubyt. zariadeniach“,“1″:“Number of overnight stays by visitors in accommodation of facilities“,“Data“:[{„Year“:“2019″,“Value“:3380394}]}}}}
Viac o harvesteri, jeho účele či „príbehu“ si môžete prečítať v príspevku „Dáta Štatistického úradu – základné údaje pre poznanie regiónu“.
ÚPSVaR
Do roku 2020 publikoval ÚPSVaR všetkých zhruba 29 štatistických ukazovateľov v jednom veľkom XLS súbore pre určité obdobie. Tieto údaje sú zaujímavé pre obyvateľov, ale sú nevyhnutné aj pre prijímanie efektívnych rozhodnutí a správne nastavenie politík PSK. Avšak v podobe jedného veľkého XLS súboru predstavovali zároveň aj veľkú komplikáciu pre ich ďalšie spracovanie a využitie. Proprietárny formát zároveň nevyhovuje štandardu pre otvorené údaje. ÚPSVaR teda vrámci pilotnej spolupráce s PSK pristúpil k zverejňovaniu týchto štatistických údajov vo formátoch XML a JSON na adrese https://www.upsvr.gov.sk/statistiky/open-data.html .
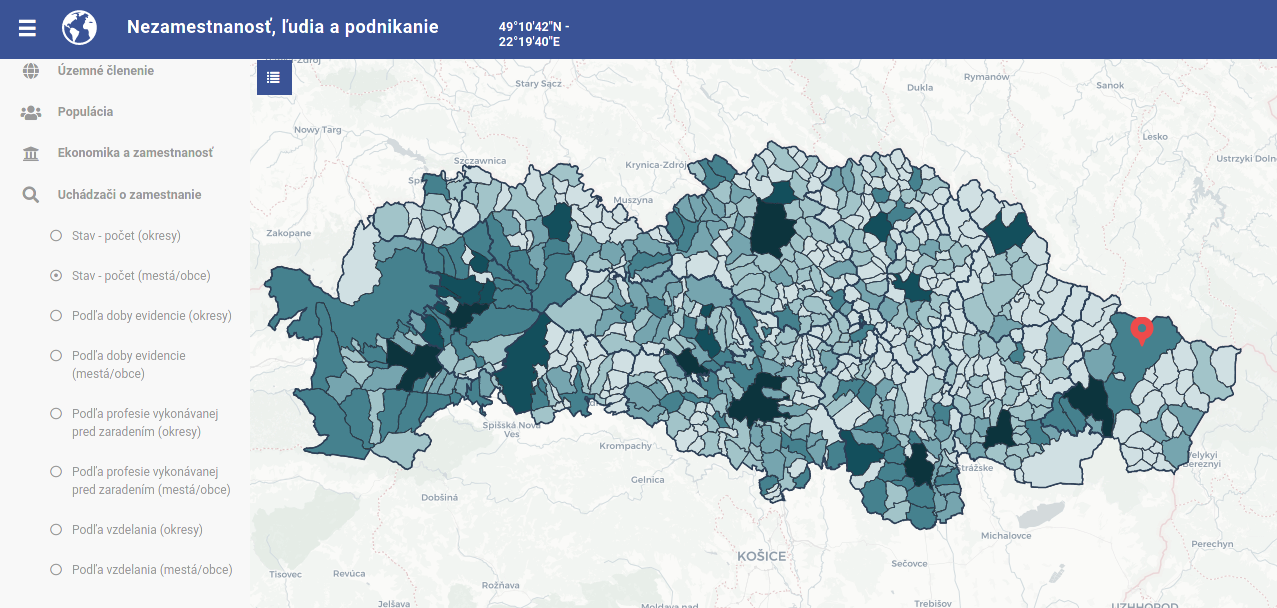
Harvester upsvar-harvester teda používa túto novú službu na udržiavanie aktuálnej kópie relevantných štatistických údajov v databáze PSK, vďaka čomu aplikácie typu „Nezamestnanosť, ľudia a podnikanie“ poskytujú relevantné prehľady bez toho, aby ich každý mesiac muselo analytické oddelenie aktualizovať – aplikácie sa aktualizujú akoby samé a teda vďaka investícii do harvesterov už len za cenu údržby harvestera.
Keďže štatistické tabuľky ÚPSVaR nie sú až také masívne, tak je zverejňovanie postavené na poskytovaní súborov (t.j. nie API, ako pri ŠÚ). Dôležitou funkciou rozhrania sú:
- stabilná štruktúra adries k súborom, t.j. https://www.upsvr.gov.sk/statistiky/open-data/<YYYY>-<MM>.html, viď upsvar_harvester.py#L113
- možnosť zistiť, či bol súbor od posledné stiahnutia aktualizovaný (pomocou už spomínaných HEAD a ETag častí HTTP protokolu), viď upsvar_harvester.py#L248-250
eVuc.sk
Informácie o zdravotnej starostlivosti v Prešovskom ale aj iných krajoch spravujú lekári a úradníci VÚC často v systéme eVuc.sk, čo je v podstate informačný systém dodaný pre VÚC komerčným subjektom. Aby Inštitút rozvoja mohol pracovať s údajmi v ňom, tak je to z technického hľadiska taká istá úloha ako v prípade údajov od ŠÚ či ÚPSVaR: dáta z externého systému treba „prelievať“ do internej databázy. Z tohto dôvodu sú použité princípy a postupy totožné ako v prípade otvorených údajov, t.j. systém eVuc.sk poskytuje API na báze XML pomocou ktorého udržiava harvester aktuálnu kópiu všetkých údajov aj v internej databáze PSK.
Z technického hľadiska je to teda harvester ako každý iný, špecifický je skôr z pohľadu organizačného resp. právneho: niektoré údaje v systéme eVuc.sk nie sú verejné a slúžia len pre interné účely toho ktorého VÚC a poskytovateľov zdravotnej starostlivosti, t.j. nie sú to otvorené údaje (Open Data). Vďaka harvesteru však vie PSK tieto údaje naviazať na svoj geoportál a ďalšiu infraštruktúru a teda vie časť týchto údajov následne poskytnúť občanom aj vo forme otvorených údajov alebo v podobe mapovej aplikácie, viď napr. aplikáciu „Zdravotná starostlivosť a sociálne služby“.
Keďže použité API eVuc.sk nie je verejné a aj údaje ním poskytované nie sú verejné, harvester zatiaľ nie je zverejnený tak, ako ostatné vyššie spomenuté. Je však potenciál využiť ho aj v iných VÚC. Prípadným záujemcom radi odovzdáme tieto cenné znalosti.
Iné
Okrem doteraz popísaných používa PSK ešte aj tieto ďalšie harvestery:
- pskpreludi.sk: Tento prípad je obdobou eVuc.sk – systém je dodaný pre PSK treťou stranou a harvester zabezpečuje dostupnosť údajov z neho aj pre potreby analytického oddelenia PSK na ďalšie využitie,
- harvester pre Covid-19 štatistiky od NCZI (v testovacej verzii).
Záver
V článku sme teda popísali ako a prečo PSK využíva pre svoj chod viaceré automatizované harvestery pre údaje z rôznych zdrojov. Cieľom bolo poukázať na to, že:
- harvestery sú nevyhnutné na budovanie analytických kapacít a vývoj širokej palety nadstavbových vizualizácií a jednoduchších aj zložitejších aplikácií
- kľúčovou informáciou je to, že počiatočná vyššia investícia do automatizovaného importu následne výrazne zjednodušuje a zlacňuje udržiavanie všetkých výstupov v užitočnom a aktuálnom stave
Zároveň sme naznačili ďalšie ponaučenia pre budovanie dátovej infraštruktúry v SR či inde:
- dôležitá je spolupráca poskytovateľov a používateľov údajov na dizajne rozhraní pre publikovanie údajov tak, aby bolo obstaranie / stiahnutie údajov čo najjednoduchšie a najspoľahlivejšie
- spolupráca všetkých zainteresovaných na vývoji a údržbe harvesterov môže pomôcť rozložiť náklady na vývoj a údržbu pre proces harvestovania, keďže ten je spoločný pre mnohých
- vhodné nastavenie procesov a ETL procedúr je dôležité pre tvorbu a udržanie výstupov (pridanej hodnoty) z harvestovaných údajov
[1]Ďalšie ETL fázy môžu využívať rovnaké princípy a spôsoby ako harvestery, dokonca aj rovnakým spôsobom, t.j. napr. jednoduchý Python kód. Alebo aj nie a teda pripadajú do úvahy aj iné postupy či nástroje: SQL view kombinujúci viaceré zdroje a tabuľky, ETL nástroje typu Talend, a pod. Ale o tom niekedy nabudúce.